Da Tek ee
A Techie's Perspective
I Have Moved
Published Sunday, May 07, 2006 by Anand Kishore.
The title says it all. Yes, I have moved. Moved from Blogger to Wordpress. Moved from Da Tek ee to Semantic Void, my new blog. And here are the reasons why.
Why Does Google Love Wikipedia?
Published Tuesday, March 14, 2006 by Anand Kishore.
With all the speculation about Google hosting Wikipedia pages and Google Reference, the question everyone seems to be asking is ''Why Does Google Love Wikipedia?". The Wikipedia is a free encyclopedia that anyone can edit. It is maintained by the people, it is for the people to use and is of the people i.e. has no central authority governing it. Its an collaborative effort where everyone contributes.
Currently Google bots crawl the abyss of the internet, parsing and indexing information from pages. All of these pages might not be useful or its content accurate or reliable from the user perspective. On the other hand the Wikipedia is moderated and maintained by the people themselves ensuring accuracy. Although the facts on Wikipedia cannot be guaranteed to be accurate but public moderation ensures that false data will be removed eventually.
Hence Google's interest in Wikipedia is evident from the fact that the people would themselves act as data sources. It is like every individual is a Google bot, feeding data right into the Google Indexer. Google would also gain from the fact that this data would be accurate which is not the case for the web crawler.
This is how I perceive Googles interest in Wikipedia. What are your views?
--
Posted by Anand Kishore to Da Tek ee > Google at 3/14/2006 07:31:00 PM
Currently Google bots crawl the abyss of the internet, parsing and indexing information from pages. All of these pages might not be useful or its content accurate or reliable from the user perspective. On the other hand the Wikipedia is moderated and maintained by the people themselves ensuring accuracy. Although the facts on Wikipedia cannot be guaranteed to be accurate but public moderation ensures that false data will be removed eventually.
Hence Google's interest in Wikipedia is evident from the fact that the people would themselves act as data sources. It is like every individual is a Google bot, feeding data right into the Google Indexer. Google would also gain from the fact that this data would be accurate which is not the case for the web crawler.
This is how I perceive Googles interest in Wikipedia. What are your views?
--
Posted by Anand Kishore to Da Tek ee > Google at 3/14/2006 07:31:00 PM
Web 2.0 : A Walled Garden?
Published Sunday, March 12, 2006 by Anand Kishore.
What does the term 'Web 2.0' denote?
I have always been skeptical about the sustainability of mashups. Although the API's the mashups use confer with the idea of Web 2.0 and promote openess and free flow of data, they are restricted in a way. For example, the search API released by Google restricts searches to thousand queries per day. Alexa for instance charges for its API usage. The question this raises is that 'Is the Web 2.0 as open as we thought?', as free as in beer.
In the mashup ecosystem the mashups can be thought of as resellers. The data providers are in control cause if they intend to discontinue sharing data or for some reason change their API, the dependant mashup will be in a fix. They can even block service to mashups they think are inappropriate.
This leads us to rethink: Is the Web 2.0 just another walled garden?
--
Posted by Anand Kishore to Da Tek ee > Web at 3/12/2006 04:12:00 PM
Web 2.0 is the network as platform, spanning all connected devices; Web 2.0 applications are those that make the most of the intrinsic advantages of that platform: delivering software as a continually-updated service that gets better the more people use it, consuming and remixing data from multiple sources, including individual users, while providing their own data and services in a form that allows remixing by others, creating network effects through an "architecture of participation," and going beyond the page metaphor of Web 1.0 to deliver rich user experiences.The Web 2.0 promotes an 'architecture of participation' by utilizing data from multiple sources and providing its own data in a form that can be utilized by others. This is evident from the numerous API's that are available on the web. Anyone with a unique idea can develop a mashup using one or more of such API's.
[via]
I have always been skeptical about the sustainability of mashups. Although the API's the mashups use confer with the idea of Web 2.0 and promote openess and free flow of data, they are restricted in a way. For example, the search API released by Google restricts searches to thousand queries per day. Alexa for instance charges for its API usage. The question this raises is that 'Is the Web 2.0 as open as we thought?', as free as in beer.
In the mashup ecosystem the mashups can be thought of as resellers. The data providers are in control cause if they intend to discontinue sharing data or for some reason change their API, the dependant mashup will be in a fix. They can even block service to mashups they think are inappropriate.
This leads us to rethink: Is the Web 2.0 just another walled garden?
--
Posted by Anand Kishore to Da Tek ee > Web at 3/12/2006 04:12:00 PM
No Bar @ BarCamp Delhi
Published Tuesday, March 07, 2006 by Anand Kishore.
BarCamp Delhi was quite an experience. I had never been to any meet as such...a first timer at BarCamp. I had heard/read a lot about the BarCamps held at US and was very much excited about its first foray into Asia especially India. BarCamp has quite a history about how it started and its connections with FooCamp. No moderation , no restrictions whatsoever was unique to BarCamp. The attendees ranged from entrepreneurs, CEOs to developers and even students. Everyone shared a single platform and participated in some way or the other. Every session consisted of a presentation follwed by an open discussion allowing free flow of ideas.
The theme "Next Generation Internet: Web 2.0, mobile computing, and other cool stuff" was quite apt wrt the current scenario of the web.
A quick summary of the sessions I attended:
--
Posted by Anand Kishore to Da Tek ee > Misc at 3/08/2006 12:40:00 PM
The theme "Next Generation Internet: Web 2.0, mobile computing, and other cool stuff" was quite apt wrt the current scenario of the web.
A quick summary of the sessions I attended:
- Agile Web Development with Ruby on Rails by Manik Juneja: Quite an eye-opener for web developers giving them an insight of how powerful Ruby on Rails is.
- Rich Internet Applications and Flex by Ramanarayanan K and Manish Jethani: An introduction to Macromedia RIA's was given followed by a live demostartion by Manish where he built a YouTube player using Flex. Flex proved to be quite promising due to its ease and platform independence.
- Making AJAX applications faster by Jonathan Boutelle: IMHO one of the most impressive presentations. Jonathan introduced us to the concepts of prefetching/preloading in terms of making AJAX applications faster. He pointed out that the decision of the amount of data to prefetch was purely heuristic and application specific.
- Can we trust next generation web applications by Kapil Bhatia: Kapil brought out some subtle points regarding trust in the current web scenario. This led to open discussions about reliability of some trusted web applications and whether we could trust them with our data. We also discussed about the sustainability of mash-ups coming to the conclusion that in the mashup ecosystem the data owner is the boss.
- How Bloggers Make Money by Amit Agarwal 'ProBlogger': Quick tips by a professional blogger from Agra on how to monetize your blogs and tyurn it into a cash cow. He compared various monetizing tools like Google AdSense, Chitika and shared his experiences regarding the same. He let out the tricks for search engine optimization of blog posts.
- Blogging Network - None of us are as smart as all of us by Ajay Sanghani: Ajay, from ITVIDYA.com, introduced us to his blogging network ITVIDYA. He brought across a very valid point that wealth earned through blogs not only consisted of the dollars from cpc but also of the social/business networking that may result.
- Web 2.0 & Power of Default by Prashant: Survival strategies of the Default were discussed concluding that the Default is the way and its here to stay. Paticipants debated on the revenue models for the Web 2.0 concluding that advertising was not the only alternative (37Signals being one of the Web2.0 companys which has a concrete revenue model other than advertising).
- Knowledge Management 2.0 - Applying structured blogging to knowledge management by Manish Dhingra: The core of the presentation was to familarise all with the concept of structured blogging. Manish also revealed Wordpress and Movable Type plugins to facilitate structured blogging. One advantage of structured blogging was to clearly differentiate between normal posts and special posts like reviews etc. This would ease the machine readability of such posts. He emphasised on Knowledge Management at the corporate level talking about the corporate-level blogs and the driving force behind them.
- Elements of Web 2.0 - Micro-content, Mobiles and Communities by VeerChand Bothra: One of the lone presentations which spoke about Mobile 2.0. Veer elaborated on the concept of MoBlogs and generation of micro-content which is independent of the platform be it th web or the mobile. He also gave the first public demo of his project MyToday. At the first glance MyToday looks like any other feed aggregator. But the twist lies in the fact that it aggregates news based on sources rather than on the content of the posts (complementary to what Google News does).
- Developing MVC based AJAX applications by Kapil Mohan: The use of MVC design pattern on the client-side was quite innovative. Advantages of it were quite evident, reorganising sloppy javascript code into a modularised, manageable code. The Model-View-Controller architecture facilitates pin pointing errors making javascript debugging a lot more easier.
- Open source Web application testing with WATiR by Angrez Singh: Another interesting presentation for all the Ruby geeks. Angrez presented the easiness with which web applications could be tested using WATiR. He pointed out its advantages over other commercial testing tools which are 'record and play' based. He also exhibhited the extension they had developed at Persistent Systems to extend WATiR for Firefox (currently WATiR works only with IE).
--
Posted by Anand Kishore to Da Tek ee > Misc at 3/08/2006 12:40:00 PM
Google Hack: Blogger Categories
Published Saturday, February 04, 2006 by Anand Kishore.
I've been using Blogger since a long time due to its association with Google. I've also tried out other blogging platforms like Wordpress etc. But the most important feature I missed in Blogger was the categories. I have a whole bunch of posts each belonging to different topics It was all too messy and cumbersome to get them organized without categorization.
If theres a problem there has to be a solution to it. There are many solutions to this category problem but I'll be explaining only one of the cleanest approaches.
First of all you need a main blog where you need categories to be implemented. Secondly you'll need a mail account with good filtering features like in Gmail. Thirdly you'll need to create a blog for every category that you want. You'll need to the follwing set up as explained:
For example consider a main blog named 'Da Tek ee'. Set the 'Mail-to-Blogger Address' to whatever you want like datekee.XXX@blogger.com. For every category blog like 'Da Tek ee > Google' set the 'BlogSend Address' to the mail address you're using for filtering purposes. In the mail account set up a filter to forward mails containing the subject "Da Tek ee > Google" to the main blogs 'Mail-to-Blogger Address'. You just finished setting up your first category. This can be done for as many categories you want.
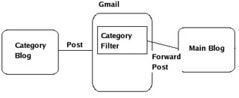
So now whenever any post is published in the category blog it is forwarded to the email address provided. Due to the filter created in the mail account the post is in turn forwarded to the main blog where it is published. Each post has link to the blog where it was originally posted (link to the category blog in our case) e.g. 'Posted by Anand to Da Tek ee > Google'.
Happy blogging until Blogger eventually comes up with the category feature (-;.
--
Posted by Anand Kishore to Da Tek ee > Google at 2/04/2006 03:20:00 PM
If theres a problem there has to be a solution to it. There are many solutions to this category problem but I'll be explaining only one of the cleanest approaches.
First of all you need a main blog where you need categories to be implemented. Secondly you'll need a mail account with good filtering features like in Gmail. Thirdly you'll need to create a blog for every category that you want. You'll need to the follwing set up as explained:
For example consider a main blog named 'Da Tek ee'. Set the 'Mail-to-Blogger Address' to whatever you want like datekee.XXX@blogger.com. For every category blog like 'Da Tek ee > Google' set the 'BlogSend Address' to the mail address you're using for filtering purposes. In the mail account set up a filter to forward mails containing the subject "Da Tek ee > Google" to the main blogs 'Mail-to-Blogger Address'. You just finished setting up your first category. This can be done for as many categories you want.
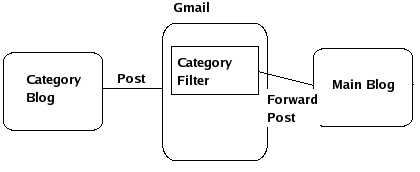
So now whenever any post is published in the category blog it is forwarded to the email address provided. Due to the filter created in the mail account the post is in turn forwarded to the main blog where it is published. Each post has link to the blog where it was originally posted (link to the category blog in our case) e.g. 'Posted by Anand to Da Tek ee > Google'.
Happy blogging until Blogger eventually comes up with the category feature (-;.
--
Posted by Anand Kishore to Da Tek ee > Google at 2/04/2006 03:20:00 PM
Range Search In Lucene
Published Friday, January 13, 2006 by Anand Kishore.
You'll be quite surprised to find out about how Lucene actually expands your range queries. As pointed out by Simon, range queries are enumerated for every possible value in the given range. Now ain't that naive >-:. This limits the range to about 1024 values. Simon also points out a possible solution for dates by indexing them as strings of the form 'yyyymmdd'.
I tried doing the same on one of my recent projects where I was indexing dates as strings 'yyyymmdd'. But when I actually had a look at my expanded query via Limo, I found Lucene enumerating for string range queries as well.
Posted by Anand Kishore to Da Tek ee > Lucene at 1/13/2006 03:13:00 PM
I tried doing the same on one of my recent projects where I was indexing dates as strings 'yyyymmdd'. But when I actually had a look at my expanded query via Limo, I found Lucene enumerating for string range queries as well.
Apparently this is not a bug nor even a feature but a "known behaviour".--
Posted by Anand Kishore to Da Tek ee > Lucene at 1/13/2006 03:13:00 PM
Tag Cloud Font Distribution Algorithm
Published Thursday, January 05, 2006 by Anand Kishore.
Ever thought of how the collection of tags with varying fontsizes (known as Tag Cloud) populated. As I say 'theres an algorithm for everything', theres an algorithm for this too. Assuming you know all about tag popularity (if not refer previous post) I'll go ahead explaining it.
The distinct feature of tag clouds are the different groups of font sizes. Now the number of such groups desired depends entirely upon the developer. Usually having six such size-groups proves optimal.
Assume any suitable metric for measuring popularity (for instance 'number of users using the tag'). We can always obtain the max and min numbers for the same. For example:
max(Popularity) = 130
min(Popularity) = 35
Therefore we can define one block of font-size as :
Font-sizes therefore could be bound as follows:
Range Font-Size
35 to 51 1
52 to 68 2
69 to 85 3
86 to 102 4
103 to 119 5
120 to 136 6
Thats as easy as it can get.
--
Posted by Anand Kishore to Da Tek ee > Tagging at 1/06/2006 12:49:00 PM
The distinct feature of tag clouds are the different groups of font sizes. Now the number of such groups desired depends entirely upon the developer. Usually having six such size-groups proves optimal.
Assume any suitable metric for measuring popularity (for instance 'number of users using the tag'). We can always obtain the max and min numbers for the same. For example:
max(Popularity) = 130
min(Popularity) = 35
Therefore we can define one block of font-size as :
( max(Popularity) - min(Popularity) ) / 6
For the above values we get one such block range as (130 - 35) / 6 = 15.83 ~ 16Font-sizes therefore could be bound as follows:
Range Font-Size
35 to 51 1
52 to 68 2
69 to 85 3
86 to 102 4
103 to 119 5
120 to 136 6
Thats as easy as it can get.
--
Posted by Anand Kishore to Da Tek ee > Tagging at 1/06/2006 12:49:00 PM
Calculation Of Tag Popularity
Published Monday, January 02, 2006 by Anand Kishore.
Determinig the popularity of tags has very fluid solutions which keep changing from application to application. But in general one metric that can be used is the number of unique items tagged using the particular tag. Secondly another metric that is the number of unique users using this tag could also be used. I've come up with a formula that encompasses both of these:
where,
Usage Count (UsgCnt) : the number of unique items having the tag.
Number of tagged Items (NTI) : the total number of items having atleast one tag (i.e. items participating in tagging)
User Count (UsrCnt) : the number of users using this tag.
Number of Taggers (NOT) : the total number of users participating in tagging.
Case 1:
UsgCnt = 15, NTI = 40, UsrCnt = 2, NOT = 20
Popularity = 0.0375
Note: This represents a case in which the two users may be trying to spam the system by tagging many items by the specific tag.
Case 2:
UsgCnt = 15, NTI = 40, UsrCnt = 9, NOT = 20
Popularity = 0.1685
Note: Here we clearly see that as the number of users using this tag increases the popularity increases as well (suggesting no spam but folksonomy).
Case 3:
UsgCnt = 15, NTI = 40, UsrCnt = 1, NOT = 1
Popularity = 0.375
Note: Here it can be noted that if there is only one user in the system the popularity becomes independent of the user ratio and depends entirely on the tagged items ratio.
Case 4:
UsgCnt = 40, NTI = 40, UsrCnt = 10, NOT = 20
Popularity = 0.5
Note: In this case if all the messages in the system are tagged using the specific tag (UsgCnt = NTI ) the popularity depends entirely on the number of users using this tag.
This gives a fairly rough idea of tag popularity calculation.
--
Posted by Anand Kishore to Da Tek ee > Tagging at 1/02/2006 02:08:00 PM
( Usage Count / Number of tagged Items ) * ( User Count / Number of Taggers )
where,
Usage Count (UsgCnt) : the number of unique items having the tag.
Number of tagged Items (NTI) : the total number of items having atleast one tag (i.e. items participating in tagging)
User Count (UsrCnt) : the number of users using this tag.
Number of Taggers (NOT) : the total number of users participating in tagging.
Case 1:
UsgCnt = 15, NTI = 40, UsrCnt = 2, NOT = 20
Popularity = 0.0375
Note: This represents a case in which the two users may be trying to spam the system by tagging many items by the specific tag.
Case 2:
UsgCnt = 15, NTI = 40, UsrCnt = 9, NOT = 20
Popularity = 0.1685
Note: Here we clearly see that as the number of users using this tag increases the popularity increases as well (suggesting no spam but folksonomy).
Case 3:
UsgCnt = 15, NTI = 40, UsrCnt = 1, NOT = 1
Popularity = 0.375
Note: Here it can be noted that if there is only one user in the system the popularity becomes independent of the user ratio and depends entirely on the tagged items ratio.
Case 4:
UsgCnt = 40, NTI = 40, UsrCnt = 10, NOT = 20
Popularity = 0.5
Note: In this case if all the messages in the system are tagged using the specific tag (UsgCnt = NTI ) the popularity depends entirely on the number of users using this tag.
This gives a fairly rough idea of tag popularity calculation.
--
Posted by Anand Kishore to Da Tek ee > Tagging at 1/02/2006 02:08:00 PM
Gmail AntiVirus Test Drive
Published Saturday, December 03, 2005 by Anand Kishore.
After all the buzz about Gmail integrating an anti-virus scanner floating around on the web since yesterday I decided to test it out myself.
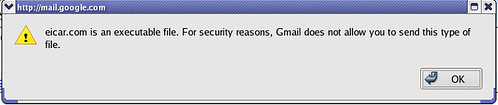
As per Gmail:
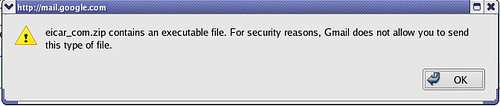
 I also tried attaching the zipped virus and the response was similar:
I also tried attaching the zipped virus and the response was similar:
 Conclusion: Gmail uses Brightmail(r) AntiVirus using Symantec's AntiVirus Technology which sure does its job well. The feature of not allowing a user to attach an infected file into the outgoing mail looks promising.
Conclusion: Gmail uses Brightmail(r) AntiVirus using Symantec's AntiVirus Technology which sure does its job well. The feature of not allowing a user to attach an infected file into the outgoing mail looks promising.
--
Posted by Anand Kishore to Da Tek ee > Google at 12/03/2005 11:55:00 PM
As per Gmail:
If a virus is found in an attachment you've received, our system will attempt to remove it, or clean the file, so you can still access the information it contains. If the virus can't be removed from the file, you won't be able to download it.So I sent the EICAR Anti-Virus test file to my account and this is what I actually recieved:
This message has been processed by Brightmail(r) AntiVirus usingthen again Gmail said:
Symantec's AntiVirus Technology.
eicar.com was infected with the malicious virus EICAR Test String and has been deleted because the file cannot be cleaned.
eicar.com was infected with the malicious virus EICAR Test String and has been deleted because the file cannot be cleaned.
eicar.com was infected with the malicious virus EICAR Test String and has been deleted because the file cannot be cleaned.
If a virus is found in an attachment you're trying to send, you won't be able to send the message until you remove the attachment.so I tried that out to by first trying to attach the eicar.com file to the outgoing mail for which Gmail responded as:
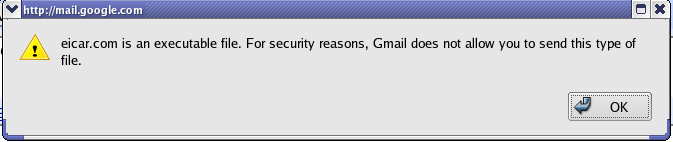 I also tried attaching the zipped virus and the response was similar:
I also tried attaching the zipped virus and the response was similar: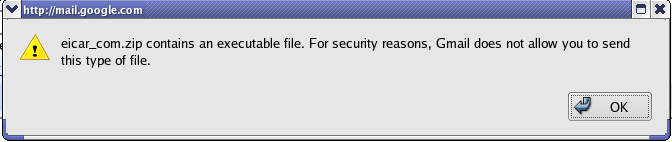 Conclusion: Gmail uses Brightmail(r) AntiVirus using Symantec's AntiVirus Technology which sure does its job well. The feature of not allowing a user to attach an infected file into the outgoing mail looks promising.
Conclusion: Gmail uses Brightmail(r) AntiVirus using Symantec's AntiVirus Technology which sure does its job well. The feature of not allowing a user to attach an infected file into the outgoing mail looks promising.--
Posted by Anand Kishore to Da Tek ee > Google at 12/03/2005 11:55:00 PM
New Google Service Idea [Gmail P2P File Sharing]
Published Friday, December 02, 2005 by Anand Kishore.
I had mailed Google about a month back regarding the new service idea I had come up with only to find yesterday that someone else too had thought of it (G2G) )-: . This is what my idea was:-
--
Posted by Anand Kishore to Da Tek ee > Google at 12/02/2005 05:24:00 PM
Hi,Lesson Learnt: "Implement your ideas (even if a prototype implementation) before someone else does it."
I came up with an idea for a new Google service and thought it would be nice to share it with you. Gmail already offers infinite storage space. This has led to people not deleting their mails but rather storing them. Now many mails do have attachments in thm which may be pictures, videos, documents, audio files etc. Its like every user has their own private online hard drive.
Now what I propse is that these attachments (not the content of mails) should be allowed to be searchable/browseable if the owner of the mail wants them to (by setting attachment permissions for that mail to public). In such a case with more and more people sharing attachments we can have a sort of online peer-to-peer file sharing system. People would then be able to search for attachments made public. This could later be evolved by enabling folksonomies (tagging).
Regards,
Anand Kishore.
--
Posted by Anand Kishore to Da Tek ee > Google at 12/02/2005 05:24:00 PM



